Neural Networks:
This is one of the most awesome Machine learning algorithms.
In the neural network, we have three components:
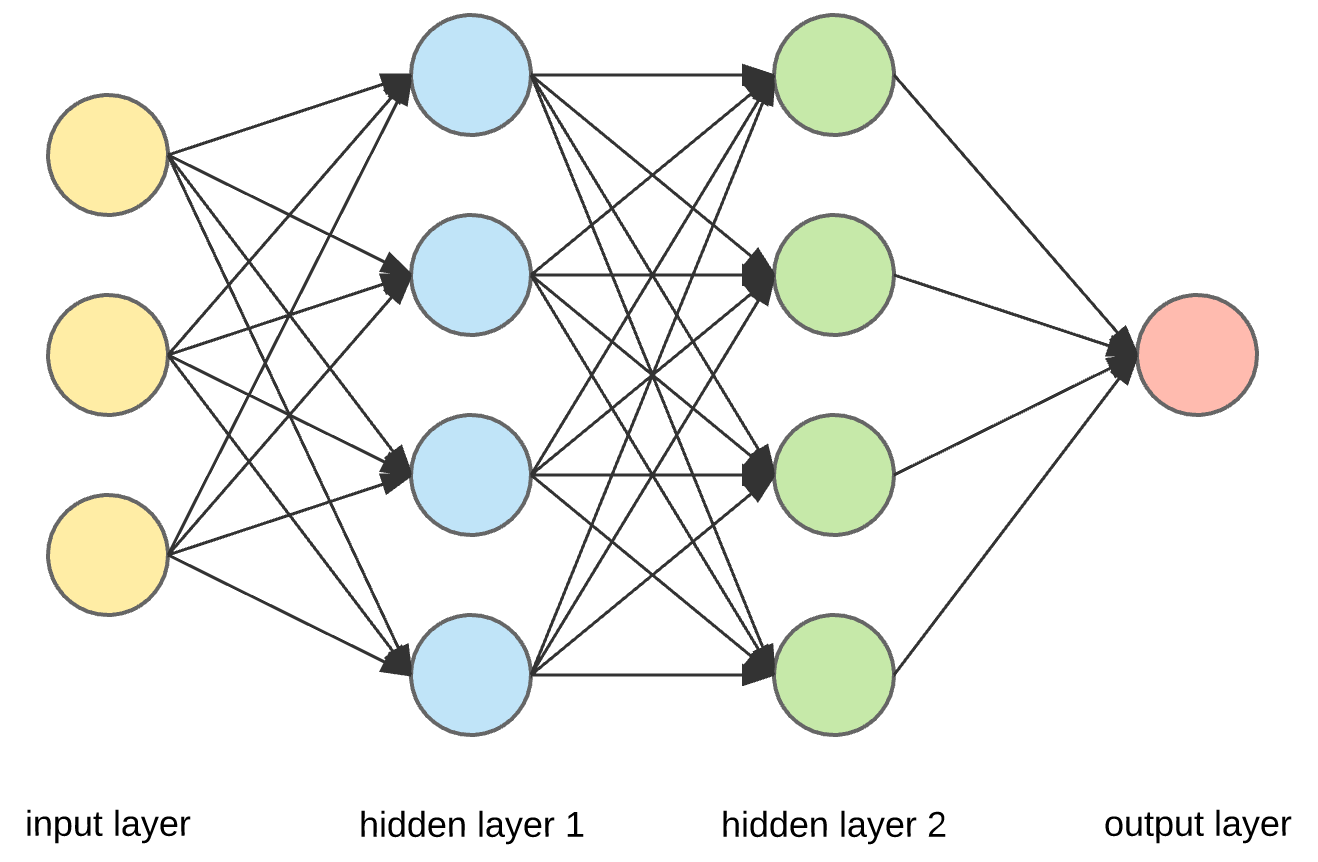
Conventions:
a(j)(i) : is the "activation" of unit i in layer j. We'll define what activation is ahead.
Theta(j): is the matrix of weights controlling the function mapping from layer j to j+1.
Consider some examples:
a(2)(1) is the activation of unit 1 in layer 2, that is the hidden layer 1. Theta(1) is the matrix of weights controlling function mapping from layer 1 to layer 2.
Input Layer:
In the input layer, we feed in the features. Thus above we have three features in the above image. Some people create an extra node for bias term, in that case, we will have four nodes and not three.
Let the input params be as x0, x1, x2.
Theta1(1)(0) will mean parameter to be multiplied to x0 to get the first node in the first hidden layer. Theta1(1)(2) will mean the parameter to be multiplied to x2 to get the first node in the first hidden layer. Finally, Theta1(3)(2) will mean the parameter to be multiplied to x2 to get the third node in the first hidden layer, so on and so forth.
It is advised you to draw, what arrow above represents which theta parameter, and also label the nodes with activations.
Evaluating activations for layer two.
\[ a(2)(1) = g(theta1(1)(0)*x0 + theta1(1)(1)*x1 + theta1(1)(2)* x2)\] recall that g is the sigmoid funcion discussed earlier.
Similarly,
\[a(2)(2) = g(theta1(2)(0)x0 + theta1(2)(1)x1 + theta1(2)(2)x2)\]
and,
\[a(2)(3) = g(theta1(3)(0)x0 + theta1(3)(1)x1 + theta1(3)(2)x2)\]
So on and so forth.
Keep calm, keep calm
I know it is complex, and trust me it is for everyone. Take a pencil and a notebook. Draw the above given neural network, label each arrow with appropriate theta parameter and each node with correct activation.
Now the activations in the second hidden layer are found exactly the same way, except that this time the Xs is replaced with the activations from layer two and theta1 is replaced with theta2. The logic and way of working are exactly the same.
Finally, the activations of hidden layer 2 are treated exactly the same way, being multiplied with theta3 this time. The sigmoid this time gives the final output.
This is difficult I know, and you'll figure it out, grab a pen and a notebook and draw it out.
Now if the layer j have 'a' units, and 'b' in layer j+1, then Thetaj will be of dimensions b*a.
Thus theta1 have dimensions 4*3 in the above image, theta2 have a dimension of 4*4 and theta3 4*1 as its dimensions.
In case you are able to figure it out on the same day, you deserve a treat. It took me days to finally claim that I know what actually happens in neural networks,
In case you are able to figure it out on the same day, you deserve a treat. It took me days to finally claim that I know what actually happens in neural networks,

No comments:
Post a Comment